
「海外SEO情報ブログ」の鈴木 謙一氏が、
国内と海外の検索マーケティング関連情報を
さらっとまとめて毎週金曜日にお届けします。

グーグルがJavaScriptを本格的に読んで実行するようになった!
Googlebotはさらに賢くなっている(Google ウェブマスター向け公式ブログ)

「検索エンジンはJavaScriptを実行できない」と一般的に言われていたが、グーグルに限って言えばそうとは限らない。
というのも、グーグルは、以前から行っていたような簡単なJavaScriptのクロールよりも、さらに進んだ形でJavaScriptを実行してその結果を解釈するようになっているようだ。そう、ブラウザで見るのと同様な状態で。
公式ブログで次のように語っている。
Google は現在、最新のウェブ ブラウザに近いコンテンツの表示、外部リソースの追加、JavaScript の実行、CSS の適用を実現しています。
ここ数か月間、Google のインデックス登録システムは、かなりの数のウェブページを JavaScript が有効な一般ユーザーのブラウザのようにレンダリングしています。
GooglebotがJavaScriptを理解する力は相当に高まっているようだ。ウェブページの表示にJavaScriptを使っているようなサイトであっても、我々人間がブラウザで見るようにそのページを見ているらしい。
そのうえで、その能力を妨げないための注意点を5項目挙げている。そのうちの1つは次のとおりだ(筆者が改行を適宜挿入)。
別々のファイルにある JavaScript や CSS などのリソースが(robots.txt などにより)Googlebot をブロックしている場合、Google のインデクシング システムは、そのサイトを一般ユーザーと同様には認識できません。
皆様のコンテンツをインデックス登録できるように JavaScript や CSS の取得を Googlebot に許可することをおすすめします。
これは、モバイル向けのウェブサイトでは特に重要です。あるページがモバイル向けに最適化されているかを Google のアルゴリズムが識別するうえで、CSS や JavaScript などの外部リソースが必要になるためです。
その他の注意点も含め、詳細は元記事で確認してほしい。
日本語で読めるSEO/SEM情報
グーグルがあなたのページを正しく表示しているかをFetch as Googleでチェック
レンダリングできるようになった(Google ウェブマスター向け公式ブログ)
グーグルは、指定したページをレンダリングしその結果を画像として表示する機能を、ウェブマスターツールのFetch as Googleに実装した。
この機能により、Googlebotが、HTMLのコードではなく、そのページを実際にどのように見ているのかを確認できる。しかもJavaScriptやCSSや画像などの外部ファイルも読み込んだうえでの状態でだ。

また、「robots.txtでブロックされている」「エラーが返る」などの理由で、レンダリングに必要なファイルにアクセスできないときは、その旨をレポートしてくれる。
JavaScriptの理解力の向上に取り組み続けていることをグーグルは先に発表していた。レンダリングに関わるJavaScriptをGooglebotが正しく実行できているかどうかを我々が検証するために、新しい機能を提供したのだ。
文字どおり、Googlebotの目に見えているページの姿を知ることができるのは、SEOにおおいに役立つだろう。
初級者OK、ゼロから始める「構造化データ」
今のSEOには避けては通れない話題(SEO HACKS公式ブログ)
検索エンジンがページのコンテンツをより正しく理解できるようにし、さらにリッチスニペットなども表示させるための「構造化データ」の理解は、今やSEOには避けて通れない。このコーナーが始まって6年目に突入したが、ここ1~2年は構造化データのピックアップが増えてきたことを筆者は実感している。
もしあなたが構造化データについて、まだほとんど何も理解していない(または自信がない)のならば、こちらの記事を読むといい。
「セマンティックとは何か?」から始まり構造化データの目的やschema.orgの記述の仕方、そして構造化データによるマークアップを支援するためにグーグルが提供するツール「データハイライター」の使い方などを、とてもわかりやすくまとめている。
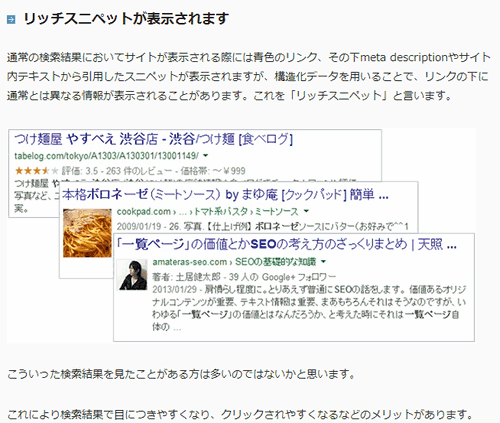
この記事だけで構造化データをマスターできるわけではないが、とっかかりとしては十分すぎるくらいの、しっかりとした内容だ。
関連語を追加して検索エンジンの評価アップを狙え!
本質は読者にとっての利益(Growth Seed)
記事のような文字コンテンツを書く場合は、どんなトピックに関して書くかは決めていることだろう。しかし、そこにさらに「関連する言葉」を含めるように意識すると、そのページのトピックを検索エンジンがよりよく理解する手がかりにできる。
こちらの記事では、テーマに関連する言葉を既存のコンテンツに追加するやり方を紹介している。こうすることで、検索エンジンのテーマ理解の助けになるかもしれないし、複合キーワードでの検索トラフィックが新たに生まれるかもしれない。
ただし、このようにして関連語を増やすことを、検索エンジン(SEO)のために行うという考え方はおすすめしない。あくまでも、「そのページを読む人にとって価値があるか」という観点で考えてほしいのだ。
語彙の少ない文章よりも、適切な語彙をつかった文章にするほうが、表現力が豊かにでき、読み手にとってもわかりやすく魅力的な内容にするための幅が拡がる。どうだろう、そのほうが、検索エンジンのために言葉づかいを変えていくよりも良い結果を生むと思わないだろうか。
また、関連語を無理に詰め込もうとすることは、逆に検索エンジンからの評価を下げることも考えられることにも注意してほしい。
訪問者にとってより価値のある情報を提供するためにも、関係する言葉が自然に含まれるように、そのジャンルに精通し文章力を高める努力をしてほしい。
ぜひ習得したいGoogleアナリティクスのイベントトラッキング
初期設定では不可能な計測が可能に(ウェブさえ)
Googleアナリティクスの初期設定では、特定のリンクのクリックやPDFファイルのダウンロード、動画の再生などを計測することはできない。そこで「イベントトラッキング」の出番がやって来る。
こちらの記事は、イベントトラッキングでよく用いられるリンクのクリック計測を中心に、イベントトラッキングの設定方法を解説している。
- イベントトラッキングとは?
- まず、イベントから
- 次は、トラッキング
- つまり、イベントトラッキングとは?
- イベントトラッキングの利用例
- 「リンクのクリック」をイベントトラッキングしてみよう
- リアルタイムでイベント発生をチェック
- リンクを個別に計測したい場合
イベントトラッキングの活用シーンは幅広い。ぜひ習得しておきたい仕組みだ。
![海外SEO情報ブログ]() 海外SEO情報ブログの
海外SEO情報ブログの
掲載記事からピックアップ
ページの読み込み高速化とグーグルのアルゴリズム更新の記事を今週はピックアップ。
- DNSプリフェッチでウェブページの読み込み速度をスピードアップ
うまく使えば速くなるかも - Google、パンダアップデート4.0 & ペイデイローンアップデート2.0を実施
穏やかになった次世代パンダ
- グーグルのJavaScript理解はまだ発展途上。画像の遅延読み込みは少し注意
- JavaScriptファイルをブロックすべきでないが例外はある
- Googlebotは、どれがオリジナル記事なのか判断するのが難しいことがある
- サイトマップに書いてはいけないURL
- 検索エンジンを操作する目的のリンクはウェブスパム
- SMX London 2014-上級SEOのためのマークアップ:マイクロデータ・スキーマとリッチスニペットについて
- SMX London 2014-新時代のリンクビルディングの取り組み方
海外のSEO/SEM情報を日本語でピックアップ
グーグルのJavaScript理解はまだ発展途上。画像の遅延読み込みは少し注意
Lazy Loadは苦手(Webmasters Stack Exchange)
ページをスクロールしていって、画像が表示される部分まで来ると、その時点で画像が読み込まれる。そういうページを見たことはないだろうか。
こういった仕組みは、「Lazy Load(レイジーロード、遅延ロード)」と呼ばれる。ページが最初に表示されるタイミングでは、スクロールしなければ出てこない場所の画像は読み込まないようにすることで、ページ表示が早く完了するようにするためのものだ。そうすることで、ユーザーエクスペリエンスを高めるのが目的だ。
こうした遅延ロードは、多くはJavaScriptで実装しており、さらに元のHTMLの作り方も通常とは異なるが、そのためのライブラリなども公開されており、すでに一般的になっている。
しかし、実はSEOには不向きな面があるようだ。
SEOフォーラムにこんな質問が投稿された。
1つのページにいくつもの画像がありLazy Loadを使って必要な画像を順に表示させている。HTMLのソースコードには画像の実際のURLは書いておらず、外部ファイルのJavaScriptで順次読み込ませている。
こうすると、SEOはマイナスだろうか。
つまり、Lazy Loadを使うと、ユーザーに見せたい画像のURLは、グーグルが読むHTMLの状態では、通常の<img>タグのsrc属性に記述されていない。そのため、画像のインデックスなどに影響があるのではないかということだ。
グーグルのジョン・ミューラー氏は次のように返答した。
noscriptタグを利用すればいいというアドバイスがフォーラムメンバーから出ていたが、noscriptタグには頼らないほうがいいだろう。なぜなら、たくさんのスパムがnoscriptを使おうとするので、noscriptの中に書かれているコンテンツを必ずしも私たちは信用するとは限らないからだ。
画像へのリンクを別途設置しておくというアイデアには賛成だ。一般的に、画像がそのページの主要な要素であるならば、普通のリンクとして埋め込むことは自然だろう(複数のサイズの画像があるならば、少なくとも1つはそのようにする)。そうすれば、必ず普通にインデックスされるはずだ。
こういったケースに適切に対応できるように私たちは取り組んでいるが、今日明日すぐに変化があるとは思えない。
検索エンジンのことを考慮に入れるなら、Lazy Loadを利用せずに画像の本当の場所を示したimgタグを、普通に使ったほうが安心なようだ。
本来ならば、Lazy Load用の画像URLとしてHTML5のカスタムデータ属性で比較的一般的に使われている「data-src」や「data-original」などの値をグーグルが理解してくれればいいのだが。
日本語記事でピックアップしたように、グーグルはJavaScriptの理解力の向上に力を入れており、実際に結果も出している。しかし、まだLazy Loadのように進歩が追いつかない技術も数多く残っていそうだ。
公式ブログでは次のように注意を促していた。
場合によっては、JavaScript が複雑すぎたり特殊すぎたりして、Google で実行できないこともあります。このような場合は、ページを完全に正しくレンダリングすることはできません。
Lazy Loadはまさにこれに該当するのだろう。
JavaScriptファイルをブロックすべきでないが例外はある
でも基本的にはクロールさせる(Matt Cutts (@mattcutts) on Twitter)
日本語記事で取り上げた、グーグル公式ブログでのJavaScriptの処理能力向上の記事で、外部のJavaScriptファイルのクロールをrobots.txtなどでブロックしないようにグーグルは注意を促していた。
これに関する、マット・カッツ氏とフォロワーのツイッターでのやりとりを紹介する。
@digitalpoint you can block specific JS in robots.txt. But in general we don't recommend that b/c it can prevent us from understanding page.
— Matt Cutts (@mattcutts) 2014, 5月 23(フォロワー): ときにはそれ(「JavaScriptファイルをrobots.txtでブロックしない」などの推奨項目)に反したほうがいいこともあります。
我々は、メールアドレスを隠すためにJavaScriptを使っていたことがありました。ですが、Googlebotはどうやってかそれを見てしまっていたことがありました。
マット・カッツ氏: (何らかの意図をもって)特定のJavaScriptファイルをrobots.txtでブロックすることは、問題ない。
だが、(そういう意図があるわけではないのならば)一般的には、おすすめできない。JavaScriptファイルをブロックしてしまうと、グーグルがページを理解するのを妨げることになってしまうからだ。
クロールをブロックする意図や目的があるのならば、JavaScriptファイルをブロックすること自体は問題ないし、そうするべきだ。逆にいうと、そういった意図や目的がないJavaScriptファイルは、基本的にはブロックせずにクロール対象としておくべきだと理解しておこう。
Googlebotは、どれがオリジナル記事なのか判断するのが難しいことがある
こちらから教えてあげよう(Matt Cutts (@mattcutts) on Twitter)
「複数の同じコンテンツが別URLで存在する場合の、どれがオリジナルかの判断」に関する、グーグルのマット・カッツ氏とフォロワーのツイッターでのやりとりを紹介する。
@KEVIN8R typically we'd try to ascertain where the blog post went live first, but that can be difficult to do with a web crawler.
— Matt Cutts (@mattcutts) 2014, 5月 23フォロワー: Blogger(グーグルが運営するブログサービス)に投稿したのとまったく同じコンテンツをLinkedIn(リンクトイン)のブログにも投稿したら、どちらが(検索結果で)勝ちますか? こういうことをやっても大丈夫ですか? それとも重複コンテンツになる悪いことですか?
マット・カッツ氏: 通常は、そのブログ記事がどこで最初に公開されたかを僕たちは突き止めようとする。だけと、ウェブのクローラにはそれが難しいことがあるんだ。
同一のコンテンツが複数の場所(サイト)で存在する場合、グーグルは、「どれがオリジナルなのか」を判断しようとする。
その手がかりの1つとして、各コンテンツが公開された時間がある。当然、オリジナルがいちばん初めに公開されているはずだからだ。
ところがGooglebotがオリジナルを常に最初に発見してくれるとは限らない。サイトのクロール頻度やクロールのしやすさなどによっては、複製側の方を先に見つけることがありうる。複製側を先に見つけてしまったら、それをオリジナルとしてみなしてしまうかもしれない。
同一のコンテンツを複数の場所で利用する場合、特定のページをオリジナルとして早く見つけてもらうための方法としては、次のようなやり方がある。
PubSubHubbubで通知する―― PubSubHubbub(パブサブハバブ)はコンテンツの公開や更新をこちらから速やかに通知する仕組み。グーグルはPubSubHubbubをサポートしている。
サイトマップを送信する―― 新しいURLを記述したサイトマップを送信し、グーグルに通知する。
Fetch as Googleでインデックスに送信する―― 新しい記事のURLにFetch as Googleを実行したあとインデックスに送信する。Googlebotの早急なクロールをリクエストできる。
+1する―― グーグルの+1ボタンを記事に設置し、それを押す。こうするとクローラが気付いて訪問してくれることがある(ただしやりすぎてスパムにならないように注意)。
コピーの掲載までに間隔を開ける―― オリジナルコンテンツがインデックスされたのを確認してから別のサイトに掲載する。
なお、先に発見されたからといって検索結果でそれが上位に必ず表示される保証はない。サイトのオーソリティ度や信頼性も関わってくる。
自分たちでコントロールできるやり方でいえば、「オリジナル以外のコンテンツから、オリジナルのコンテンツにリンクを張っておく」というやり方は有効だといわれている。
サイトマップに書いてはいけないURL
インデックスさせるURLだけを書く(Google Webmaster Help Forum)
サイトマップには、インデックスさせたいURLを正確に記述しなければならない。
グーグルのジョン・ミューラー氏が公式ヘルプフォーラムでこのように注意した。
次に示すような、検索結果に出す必要がないURLはサイトマップには含めてはならない。再確認しておこう。
- 404エラーのページ
- リダイレクト元のページ
- 重複するURL(優先するURLだけを記載する)
- noindex robots metaタグを記述してあるページ
- robots.txtでブロックしているページ
検索エンジンを操作する目的のリンクはウェブスパム
どんな形態であれガイドライン違反(Google Webmaster Help Forum)
英語版のグーグル公式ヘルプフォーラムで、こんな質問が投稿された。
フォーラムのプロフィールページから何本かバックリンクを張りました。URLのままでのリンクです。
ランキングに悪い影響が出るでしょうか。
グーグルのジョン・ミューラー氏は次のように釘を刺した。
はっきりさせておきたいことがある。
検索エンジンを操作できると目論んで他人のフォーラムに自分のサイトへのリンクを設置しているのだとしたら、それはウェブスパムと見なされ、アルゴリズムと手動ウェブスパムチームの対象になっているだろう。
リンクを設置するサイトのPageRankがどのくらいかは問題ではないし、.gov(米政府系サイトのドメイン名)かどうかも問題ではない。
フォーラムを見ている人にそのリンク経由でサイトを訪問してもらいたいという意図ではなくリンクを設置しているのならば、あなたがやっていることは、私たちにとってはウェブスパムだとみなされるだろう。
グーグルのような検索エンジンがどのように自分のサイトを見ているかを気にかけるのなら、他のサイトに置いてきたそうしたリンクをすべて削除することを勧める。そして、この先はもうそういったことはしないことだ。
もはや詳しい説明は不要だろう。「検索順位を上げる」ことを目的にして、人工的に作り上げたリンクは何であれガイドライン違反になりうる。
![SEO Japan]() SEO Japanの
SEO Japanの
掲載記事からピックアップ

先週に引き続き、SEO Japanの運営元アイオイクスさんの社員が参加したSMX Londonカンファレンスのレポート記事をピックアップ。
- SMX London 2014-上級SEOのためのマークアップ:マイクロデータ・スキーマとリッチスニペットについて
海外カンファレンスでも構造化データはホットなトピック - SMX London 2014-新時代のリンクビルディングの取り組み方
日本では難しいかもしれないが参考に

鈴木 謙一(すずき けんいち)
「海外SEO情報ブログ」の運営者。株式会社セルフデザイン・ホールディングスの取締役インディペンデント・コントリビュータ。
海外SEO情報ブログは、SEOに特化した日本ではもっとも有名なSEO系ブログの1つ。米国発の最新のSEO情報を中心に、コンバージョン率アップやユーザーエクスペリエンス最適化のための施策も取り上げている。
正しいSEOをウェブ担当者に習得してもらうために、ブログでの情報発信に加えて所属先のセルフデザインでは、セミナー講師や講演スピーカーを主たる役割にしている。
- 内容カテゴリ:SEO
- コーナー:海外&国内SEO情報ウォッチ
※このコンテンツはWebサイト「Web担当者Forum - 企業ホームページとネットマーケティングの実践情報サイト - SEO/SEM アクセス解析 CMS ユーザビリティなど」で公開されている記事のフィードに含まれているものです。
オリジナル記事:グーグルがJavaScriptを本格的に読んで実行するようになった! など10+4記事 [海外&国内SEO情報ウォッチ] | Web担当者Forum
Copyright (C) IMPRESS BUSINESS MEDIA CORPORATION, an Impress Group company. All rights reserved.